Effects of AI in Finance
Unraveling the Tapestry: Effects of AI in Finance Introduction: In the dynamic landscape of finance, the integration of Artificial Intelligence…
UNIK DATA CAPTURE
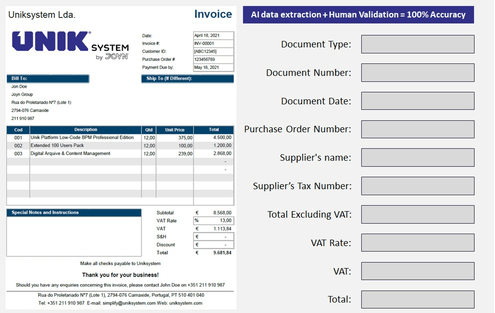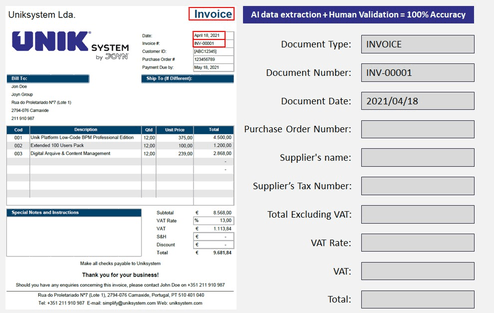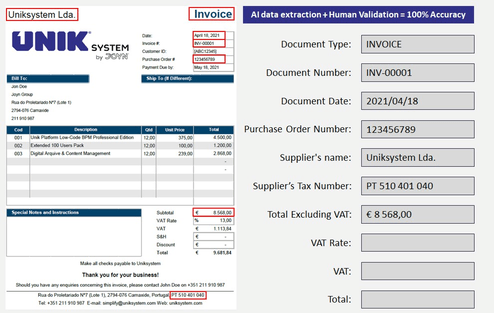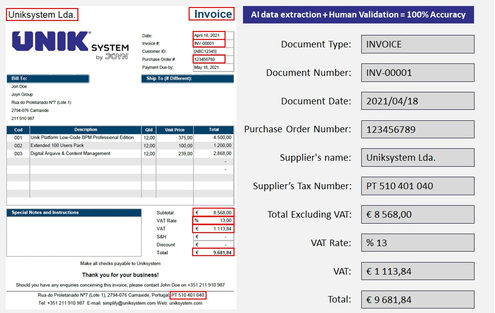
Convert documents into structured
data with 99% accuracy
Reduce costs
by 50 – 80%
Uniksystem Intelligent Data Capture solution extracts key information from documents using AI and machine learning, alongside human-in-the-loop revision to deliver 100% accurate document processing. You can fully automate your information systems by gathering structured data and integrating it easily into your existing core systems (ERP and others).
Built with Unik platform (Capterra) for Hyper Automation.
Automation and agility that traditional solutions can’t match

We process any content, structured or unstructured, from an email to a PDF or photo.

We provide 100% accurate and structured data, ready to import into your core system (ERP).

Assign approval rules and workflows according to your processes and document types.

Our price model assumes a direct return on investment of 50-80% versus your current cost.

Try it before you Buy it.
Request a proof of concept.

Platform security and scalability frequently audited by banks and financial organizations.

Unraveling the Tapestry: Effects of AI in Finance Introduction: In the dynamic landscape of finance, the integration of Artificial Intelligence…

Gartner Identifies 5 Top Use Cases for AI in Corporate Finance Introduction: In the fast-evolving landscape of corporate finance, artificial…

IDP – Intelligent Document Processing We propose you a Challenge! Imagine that, using Artificial Intelligence, it was possible to upload…
Traditional OCR solutions do not guarantee the reliability of the data extracted and it’s up to the client to constantly validate all the information—even if it’s the wrong information!
Data Capture contractually delivers all data with 100% accuracy, which means no operational costs for you related to manually validating the information.
Traditional OCRs, commonly offered by scanning brands, require you to invest in the configuration of each type of document in order to learn how to extract data from pre-configured fields. If the original document layout undergoes any changes, the system stops being able to extract that data until the new layout is configured in the system, leading to information loss.
Data Capture does not require any setup investment, meaning that the extraction of information from documents is independent of their format or layout. Since it’s an artificial intelligence and machine learning process that interprets data and not data fields, it’s constantly teaching the system about new types of data to be extracted.
The existing solutions in the market require you to already have document management and workflow solutions on top of the data extraction solution.
Luckily, Data Capture combines document scanning, information extraction, and processing from A to Z. It also has a built-in low-code platform following the BPM methodology that is compatible with BPMN.
Traditional OCR solutions require complex and lengthy implementation, set-up, and time spent adjusting processes in order to fully configure document layouts and data fields.
With Data Capture you’ll be up and running in only a couple of hours and, within 2 weeks, we’ll be done with all the document management workflow support (and relevant data). Additionally, Data Capture is instantly compatible with all types of documents you might be processing.
You’ll find that most OCR solutions ask for a high initial investment for setup and support efforts, and a continuous cost for licensing and internal support teams.
The direct ROI from your investment with Data Capture sits above 60% from the get-go, since it will be no longer necessary to allocate your teams to low added value tasks. Our solution delivers 100% reliable data and allows for a document processing protocol adjusted to your needs.
Tell us about you and the main goals you want to achieve with Data Capture Automation, and we will be in touch to reserve your deep-dive presentation.